
Summary
- Estimator is a statistic intended to approximate a parameter governing the distribution of the data.
- Estimator is denoted by a hat i.e
denotes an estimator of
.
- Sample Mean :
- Sample variance:
- An estimator is said to be consistent if the variance of the estimator tends to zero as
- An absolute efficiency of an estimator as the ratio between the minimum variance and the actual variance.
- An estimator

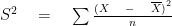

In statistics, estimation refers to the process by which one draws certain conclusions about a population, based on information obtained from a sample.
An estimator is any quantity calculated from the sample data which is used to give information about an unknown quantity in the population. Much of the theory of statistics is called Estimators. We can also say estimator is a statistic intended to approximate a parameter governing the distribution of the data.
To understand what statistic is let’s assume we have some data:

Statistic can be explained as a random variable R that is a function of the data D and can be written in the form R = f(D).
Estimator is denoted by a hat i.e 
Sample Mean
Sample Mean is defined as
Sample variance
And sample variance is defined as
Remember that the best or most efficient estimator of a population parameter is one which give the smallest possible variance. Also an estimator is said to be consistent if the variance of the estimator tends to zero as 
Bias and Unbiased of Estimator
Let’s now move on to discuss what bias and unbiased of estimator is.
We can say that a bias of an estimator

Secondly, an estimator 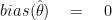
Example #1
Q. A distribution has a known mean 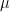


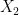

Solution:


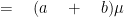
For an unbiased estimator:
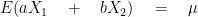
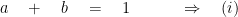
For an efficient estimator we require:

Now:




As we know from equation 1:
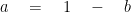
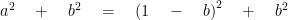



Hence:


Therefore we can conclude that 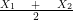
Reference
- https://books.google.co.uk/books?id=-DldDwAAQBAJ&pg=PA138&dq=a+level+estimators+statistics&hl=en&sa=X&ved=0ahUKEwiK272h7fLfAhXNRBUIHTPaCTQQ6AEINzAC#v=onepage&q=a%20level%20estimators%20statistics&f=false
- http://www.bo.astro.it/~school/school09/Presentations/Bertinoro09_Cristiano_Porciani_1.pdf
- https://www.youtube.com/watch?v=6GhSiM0frIk