
Summary
- The mean, median and mode are all measures of the center of a set of data. The skewness of the data can be determined by how these quantities are related to one another
- By studying the shape of the data we can discover the relation between the mean, median and mode
- Pearson’s first method uses mode and it’s formula is:
- The second formula of skewness uses the median and is denoted by:
- Bowley’s method of measuring skewness by quartiles is:



To recall, we studied in the previous chapter of ‘Averages’ about the mean, median and mode and how we find them using different formulas.
We said that in general these do not give the same numerical value for a given set. However, if we do find that all three give the same numerical value then the data is known as symmetrical data. Hence it can be said that this is a good way to verify whether the dataset is symmetric or not.
There are other type of dataset is known as asymmetrical data. Asymmetrical distributions are skewed where skewness measures the departure from symmetry.
If the mean > median it indicates that the distribution is positively skewed.
If the mean is < median it indicates that the distribution is negatively skewed.

We can also measure the skewness of the data using Karl Pearson’s measure of skewness, he developed two methods to find skewness in a sample.
The first method uses mode and it’s formula:

However, this method is not considered very stable in data’s where mode is made up of too few pieces as it won’t be considered a very strong measure of central tendency.
For example in the first data set below 8 only occurs twice, so while using Pearson’s first formula of skewness you have to be cautioned as it won’t be a good measure of central tendency. However in the second set you can see that 8 appears ten times thus, you can use the Pearson’s measure of skewness as you know it will give you a more stable and reliable result.
Set 1 = [1, 2, 3, 4, 5, 8, 7, 8]
Set 2= [1, 5, 6, 7, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8]
Moreover, Pearson’s second formula of skewness uses the median and is denoted by:

Karl Pearson’s coefficient of skewness lies between -3 and +3.
If SK = 0 then we can say that the frequency distribution is normal and symmetrical.
If SK < 0 then we can say that the frequency distribution is negatively skewed.
If SK > 0 then we can say that the frequency distribution is positively skewed.
Example #1
Q. The age (in years) of 6 randomly selected students from a class are:
[22, 25, 24, 23, 24, 20]
Find the Karl Pearson’s coefficient of skewness.
Solution:
STEP#1
We will first find the mean.
REMEMBER: For mean we first add all the data together and then divide it by the total number of numbers.
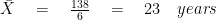
STEP#2
We will now find the median.
REMEMBER: For median we pick the middle value of the set
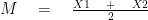

STEP#3
Find the variance first and then take its unroot for Standard deviation.

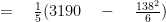



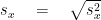


STEP#4
Put it all into Pearson’s equation to get:

As you can tell the value of SK< 0 thus we can say that the data is negatively skewed.
Additionally, there is another way of measuring the skewness and that is by the Bowley’s method it is used when the given distribution has open end class.
Bowley’s coefficient of skewness lies between -1 and +1. Bowley’s and Pearson’s method both give the similar conclusion regarding the skewness of the data.
If SK = 0 then we can say that the frequency distribution is normal and symmetrical.
If SK < 0 then we can say that the frequency distribution is negatively skewed.
If SK > 0 then we can say that the frequency distribution is positively skewed.
Note: For a positively skewed data the coefficient will be positive and for a negatively skewed data the coefficient will be negative.
Example#2
The following table gives the number of children of 80 families in a village.
| No. of children | 0 | 1 | 2 | 3 | 4 | 5 |
| No. of families | 12 | 23 | 16 | 9 | 10 | 10 |
Find the Bowley’s coefficient of skewness.
Solution:
STEP#1
We will first find the quartiles.
For the first quartile:
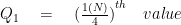
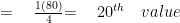
For the second quartile:

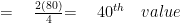
For the third quartile:
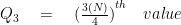

STEP#2
We will now put it in the Bowley’s equation:

Since the coefficient of skewness is SB > 0 thus, it can be said that that distribution is positively skewed.
References
- https://www.google.com.pk/search?q=positively+skewed&rlz=1C1AVNG_enGB624GB668&source=lnms&tbm=isch&sa=X&ved=0ahUKEwiuqs6D5YvfAhUUThUIHTPBCg8Q_AUIDigB&biw=1164&bih=598#imgrc=tUJMDSBABLfcuM:
- https://vrcacademy.com/tutorials/karl-pearson-coefficient-skewness-ungrouped-data/
- https://vrcacademy.com/tutorials/bowleys-coefficient-skewness-grouped-data/
- Statistics 1 by J.S Abdey